6.4.1 RDD编程基础
1 RDD创建
1 从文件系统中加载数据创建RDD
- Spark采用textFile()方法来从文件系统中加载数据创建RDD
- 该方法把文件的URI作为参数,这个URI可以是:
- 本地文件系统的地址
- 或者是分布式文件系统HDFS的地址
- 或者是Amazon S3的地址等等
从本地文件系统加载数据,创建RDD
val lines=sc.textFile(“file:///home/hadoop/spark/word.txt”)
从分布式文件系统HDFS中加载数据
val lines=sc.textFile(“hdfs://localhost:9820/input/word.txt”)
val lines=sc.textFile(“/input/word.txt”)

2 通过并行集合(数组)创建RDD
可以调用SparkContext的parallelize方法,在Driver中一个已经存在的集合(数组)上创建。
val array = Array(1,2,3,4,5)
val rdd = sc.parallelize(array)
val list = List(1,2,3,4,5)
val rdd = sc.parallelize(list)2 RDD操作
Hint
惰性计算(Lazy Evaluation) 是一种计算策略,指的是计算操作在实际需要结果时才会执行,而不是在声明时立即执行。这种策略可以优化计算效率,避免不必要的操作,并为更复杂的计算提供优化机会。
1. 转换操作
- 对于RDD而言,每一次转换操作都会产生不同的RDD,供给下一个“转换”使用
- 转换得到的RDD是惰性求值的,也就是说,整个转换过程只是记录了转换的轨迹,并不会发生真正的计算,只有遇到行动操作时,才会发生真正的计算,开始从血缘关系源头开始,进行物理的转换操作
val lines=sc.textFile(“file:///home/hadoop/module/spark/word.txt”) //file后面三个“/”,有一个/是根目录的意思
val linesWithSpark = lines.filter(line => line.contains(“Spark”)) //只记录操作,不真实计算

val data = Array(1,2,3,4,5)
val rdd1 = sc.parallelize(data)
val rdd2 = rdd1.map(x=>x+10)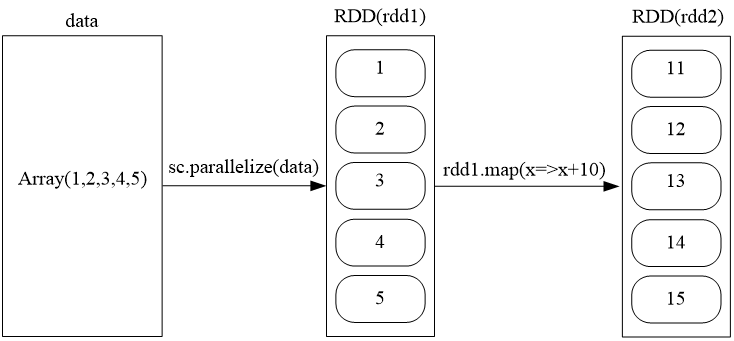
val lines=sc.textFile(“file:///home/hadoop/module/spark/word.txt”)
val linesWithSpark = lines.map(line => line.split (“ ”)) //得到三个元素
val lines=sc.textFile(“file:///home/hadoop/module/spark/word.txt”)
val words = lines.flatMap(line => line.split (“ ”)) //得到九个元素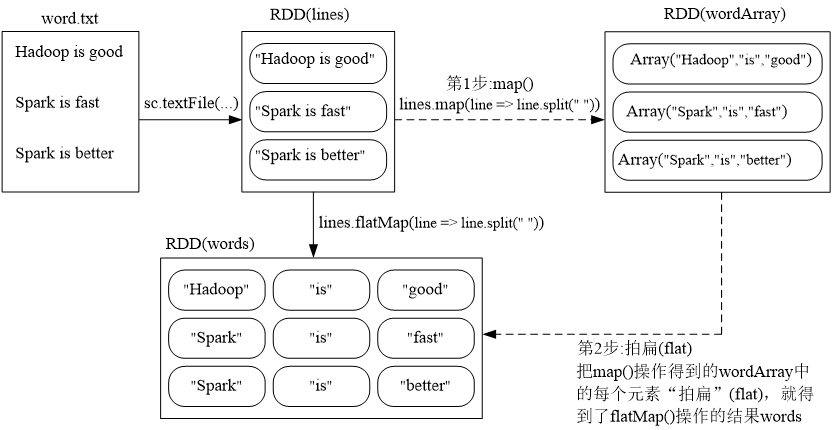
val lines=sc.textFile(“file:///home/hadoop/module/spark/word.txt”)
val words = lines.flatMap(line => line.split (“ ”))
val wordPairs = words.map( word => (word,1))
val wordGroup = wordPairs.groupByKey()
//没有ruducebykey效率高,操作仍然不会触发
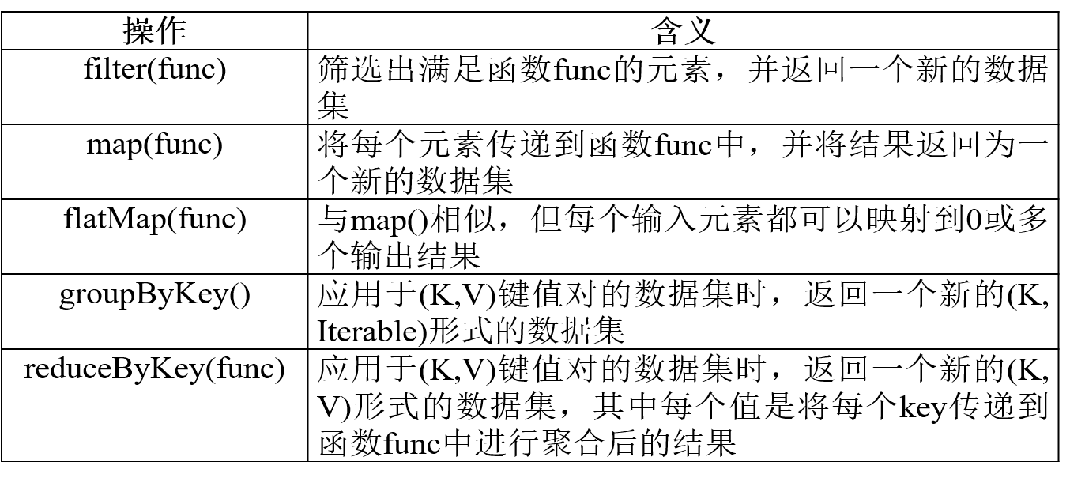
- groupByKey()应用于(K,V)键值对的数据集时,返回一个新的(K, Iterable)形式的数据集

Note
对groupbykey的解释
Partitioning:首先,Spark 会根据 RDD 的分区情况将数据进行划分,然后根据键(即单词)来决定每个键值对应该进入哪个分区。这个过程会依赖于一个 hash partitioning 策略,即根据键的哈希值决定数据的分区。
Shuffle:当数据被划分到不同的分区后,Spark 会进行一个 shuffle 操作,交换数据以确保相同的键(即单词)会被放置在相同的分区。
Group:在每个分区内,Spark 会根据键对值进行分组。每个键将对应一个 Iterable,包含所有具有相同键的值
由于 groupByKey 会产生 shuffle 操作,所以它通常被认为是一个性能较差的操作,特别是在处理大量数据时。通常建议在需要对键进行聚合时,使用 reduceByKey 或 combineByKey,这两者通常更高效,因为它们在 shuffle 之前就进行了局部聚合,减少了传输的数据量。
val lines=sc.textFile(“file:///home/hadoop/module/spark/word.txt”)
val words = lines.flatMap(line => line.split (“ ”))
val wordPairs = words.map( word => (word,1))
val wordCount = wordPairs.reduceByKey((a,b)=>a+b)
也可以
val wordCount = wordPairs.reduceByKey( _ + _ )
reduceByKey(func)应用于(K,V)键值对的数据集时, 返回一个新的(K, V)形式的数据集,其中的每个值是 将每个key传递到函数func中进行聚合后得到的结果
rdd.reduceByKey((a,b)=>a+b)
<“Spark”,<1,1,1>> => <“Spark”,3>
2. 行动操作
行动操作是真正触发计算的地方。Spark程序执行到行动操作时,才会执行真正的计算,从文件中加载数据,完成一次又一次转换操作,最终,完成行动操作得到结果

- take(n) 以数组的形式返回数据集中n个元素
- top(n) 返回数据集中前n个元素
3. 惰性机制
所谓的“惰性机制”是指,整个转换过程只是记录了转换的轨迹,并不会发生真正的计算,只有遇到行动操作时,才会触发“从头到尾”的真正的计算
val lines = sc.textFile(“file:///home/hadoop/module/spark/README.MD”)
val lineLengths = lines.map(s => s.length)
val totalLength = lineLengths.reduce((a,b) => a+b)3 持久化 (记忆策略)
在Spark中,RDD采用惰性求值的机制,每次遇到行动操作,都会从头开始执行计算。每次调用行动操作,都会触发一次从头开始的计算。这对于迭代计算而言,代价是很大的,迭代计算经常需要多次重复使用同一组数据
scala> val list = List("Hadoop","Spark","Hive")
list: List[String] = List(Hadoop, Spark, Hive)
scala> val rdd = sc.parallelize(list)
rdd: org.apache.spark.rdd.RDD[String] = ParallelCollectionRDD[22] at parallelize at <console>:29
scala> println(rdd.count()) //行动操作,触发一次真正从头到尾的计算
scala> rdd.map(s => s.length).collect.foreach(println) //重新从头计算- 可以通过持久化(缓存)机制避免这种重复计算的开销
- 可以使用persist()方法对一个RDD标记为持久化
- 之所以说“标记为持久化”,是因为出现persist()语句的地方,并不会马上计算生成RDD并把它持久化,而是要等到遇到第一个行动操作触发真正计算以后,才会把计算结果进行持久化
- 持久化后的RDD将会被保留在计算节点的内存中被后面的行动操作重复使用
persist()的圆括号中包含的是持久化级别参数,不重要
scala> val list = List("Hadoop","Spark","Hive")
list: List[String] = List(Hadoop, Spark, Hive)
scala> val rdd = sc.parallelize(list)
rdd: org.apache.spark.rdd.RDD[String] = ParallelCollectionRDD[22] at parallelize at <console>:29
scala> rdd.cache() 或者rdd.persist()
scala> println(rdd.count()) //行动操作,触发一次真正从头到尾的计算,并把rdd放入缓存
scala> rdd.map(s => s.length).collect.foreach(println) //不需要重新从头计算,使用缓存中的rdd4 分区
RDD是弹性分布式数据集,通常RDD很大,会被分成很多个分区,分别保存在不同的节点上 1.分区的作用 (1)增加并行度 (2)减少通信开销,ppt中的例子是表的链接,不是很准确
设置分区的个数
(1)创建RDD时手动指定分区个数
在调用textFile()和parallelize()方法的时候手动指定分区个数即可,语法格式如下:
sc.textFile(path, partitionNum)
//其中,path参数用于指定要加载的文件的地址,partitionNum参数用于指定分区个数。
scala> val array = Array(1,2,3,4,5)
scala> val rdd = sc.parallelize(array,2) //设置两个分区(2)使用reparititon方法重新设置分区个数
通过转换操作得到新 RDD 时,直接调用 repartition 方法即可。例如
scala> val data = sc.textFile("file:///home/hadoop/module/spark/word.txt",2)
scala> data.partitions.size //显示data这个RDD的分区数量
res2: Int=2
scala> val rdd = data.repartition(1) //对data这个RDD进行重新分区
scala> rdd.partitions.size
res4: Int = 1(3).自定义分区方法
Spark提供了自带的HashPartitioner(哈希分区)与RangePartitioner(区域分区),能够满足大多数应用场景的需求。与此同时,Spark也支持自定义分区方式,即通过提供一个自定义的Partitioner对象来控制RDD的分区方式,从而利用领域知识进一步减少通信开销 要实现自定义分区,需要定义一个类,这个自定义类需要继承org.apache.spark.Partitioner类,并实现下面三个方法:
- numPartitions: Int 返回创建出来的分区数
- getPartition(key: Any): Int 返回给定键的分区编号(0到numPartitions-1)
- equals() Java判断相等性的标准方法
5 一个综合实例
6.4.2 键值对RDD
1创建
(1)第一种创建方式:从文件中加载 可以采用多种方式创建Pair RDD,其中一种主要方式是使用map()函数来实现
scala> val lines = sc.textFile("file:///home/hadoop/module/spark/word.txt")
scala> val pairRDD = lines.flatMap(line => line.split(" ")).map(word => (word,1))
scala> pairRDD.foreach(println)(2)第二种创建方式:通过并行集合(数组)创建RDD 可以采用多种方式创建Pair RDD,其中一种主要方式是使用map()函数来实现
scala> val list = List("Hadoop","Spark","Hive","Spark")
scala> val rdd = sc.parallelize(list)
scala> val pairRDD = rdd.map(word => (word,1))
scala> pairRDD.foreach(println)
(Hadoop,1)
(Spark,1)
(Hive,1)
(Spark,1)2转换操作
- reduceByKey(func)
- groupByKey()
- sortByKey()
- keys
- keys只会把Pair RDD中的key返回形成一个新的RDD
- values
- values只会把Pair RDD中的value返回形成一个新的RDD
- sortByKey()
- sortByKey()的功能是返回一个根据键排序的RDD
- mapValues(func)
- 对键值对RDD中的每个value都应用一个函数,但是,key不会发生变化
- join
- join就表示内连接。对于内连接,对于给定的两个输入数据集(K,V1)和(K,V2),只有在两个数据集中都存在的key才会被输出,最终得到一个(K,(V1,V2))类型的数据集values