参考网课数据结构-青岛大学-王卓-第六周
参考书籍《数据结构C语言版第二版》 中国工信出版集团 人民邮电出版社出版 严蔚敏 编著
串的基本定义
即字符串,是一种有内容限制的表
关于串的几个术语
- 串名
- 串值
- 串长
- 空串
- 子串,类比子集
- 真子串,类比真子集
- 主串,类比父集
- 字符位置,下标
- 子串位置,子串中的第一个字符在主串中的字符位置
- 空格串,与空串相区分
- 串相等,长度和内容都完全相同
- 所有空串都是相等的
串的类型定义
串的顺序存储结构
# define MAXLEN 255
typedef struct{
char ch[MAXLEN+1]; //在此处限制只能为字符类型
int length;
}SString串的链式存储结构
# define CHUNKSIZE 80 //此处定义每个块的大小
typedef struct Chunk{
char ch[CHUNKSIZE];
struct Chunk *next; //每个块的头指针
}Chunk;
typedef struct{
Chunk *head, *tail; // 串的头尾指针
int curlen; // 串的当前长度
}LString;
Note
在串的实际存储时候,多用的是顺序存储,因为插入在串中没有索引常用。
串的模式匹配算法
BF算法(Brute-Force)
算法思路

Note
S串为主串(对应指针i),T串为样本串(对应指针j)。
算法实现
int Index_BF(SString S, SString T, int pos){//pos表示开始位置
int i=pos, j=1;
while (i<=S.length && j<=T.length){
if(S.ch[i]==T.ch[j]) {++i;++j;}
else {i=i-j+2;j=1;}//主串指针i要进行回位,i在比较中移动的长度记录在j的值里
}
if(j>=T.length) return i-T.length;
else return 0;
}具体的算法演示
#include <iostream>
#include <cstring> // for strlen
using namespace std;
#define MAXLEN 255
typedef struct{
char ch[MAXLEN + 1]; // Array for storing characters
int length; // Length of the string
} SString;
// Function to create an SString from a regular C string
void StrAssign(SString &S, const char *str) {
int len = strlen(str);
if (len > MAXLEN) len = MAXLEN; // Truncate if too long
S.length = len;
for (int i = 0; i < len; ++i) {
S.ch[i + 1] = str[i]; // Use 1-based indexing for SString
}
}
// Brute-force substring search
int Index_BF(SString S, SString T, int pos) {
int i = pos, j = 1;
while (i <= S.length && j <= T.length) {
if (S.ch[i] == T.ch[j]) {
++i;
++j;
} else {
i = i - j + 2;
j = 1;
}
}
if (j > T.length) return i - T.length;
else return 0;
}
int main() {
SString a, b;
int c;
// Assign strings to SString structures
StrAssign(a, "abcacbcde");
StrAssign(b, "bcd");
// Search for bcd in abcacbcde starting from position 3
c = Index_BF(a, b, 3);
cout << c << endl;
return 0;
}BF时间复杂度
坏结局:千米那n-m次部分都匹配到子串的最后一位,比较了(n-m)*m次。
算法复杂度在m<<n时,为
KMP算法(K,M,P为三个狠人的人名首字母)
在BF算法的基础上,利用部分匹配的结果,控制i不用回溯,j不用完全回溯。
j的回溯位置通过next[j]函数记录。
算法实现
int Index_BF(SString S, SString T, int pos){//pos表示开始位置
int i=pos, j=1;
while (i<=S.length && j<=T.length){
if(S.ch[i]==T.ch[j]) {++i;++j;}
//原本else {i=i-j+2;j=1;}
else
j=next[j];// i不变,j后退
}
if(j>=T.length) return i-T.length;
else return 0;
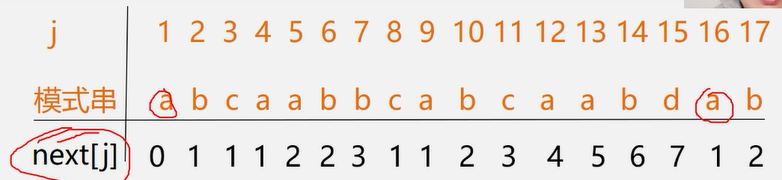
}==next函数==
- 第一个一定是0
- 第二个一定是1
- 第三个开始,值取首尾最长重复序列长度+1
Note
关于
第三个开始,值取首尾最长重复序列长度+1的解释: 如图所示,在第七位的b对应的相邻前两个是ab,在序列头的前两个也是ab,所以最长重复序列的长度为2,再加1得到3。
next函数的改进:nextval
可以更快处理模式序列前部高度重复的情况。

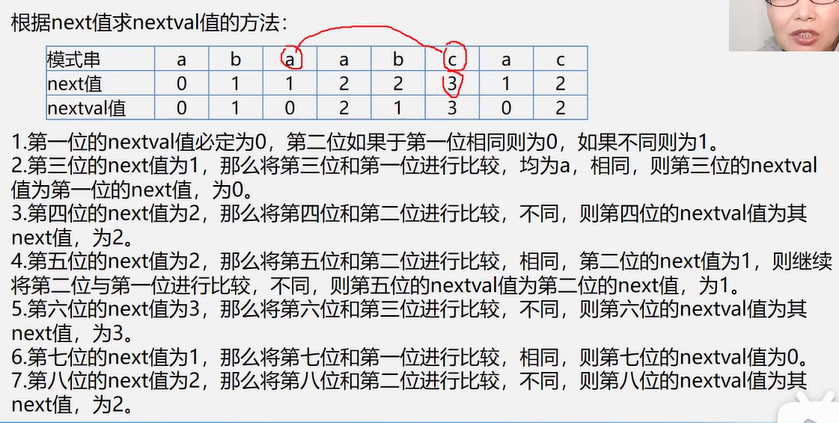
修正后的算法:
